
背景
在推荐领域较流行的深度模型方案:
实战:阿里MLR、阿里DIN、阿里ESSM、京东强化学习推荐、facebook个性化推荐dlrm、Deep Neural Networks for YouTube Recommendations、华为DeepFM、google2016 wide&deep learning、googleDeep&Cross Network等。
DeepFm模型及进化:XDeepFM(deep进化)、AFM(加入attention)、FFM(field-aware)、PNN、FNN、NFM等。
其中,DeepFM在论文中通过大量实验证明,DeepFM的AUC和Logloss都优于目前的最好效果。效率上,DeepFM和目前最优的效果的深度模型相当。在Benchmark数据集和商业数据集上,DeepFM效果超过目前所有模型。
Q1:FM解决什么问题?
1、普通的线性模型,我们都是将各个特征独立考虑的,并没有考虑到特征与特征之间的相互关系。
为了表述特征间的相关性,我们采用多项式模型。
在多项式模型中,特征xi与xj的组合用xixj表示。为了简单起见,我们讨论二阶多项式模型。
2、与线性模型相比,FM的模型就多了后面特征组合的部分。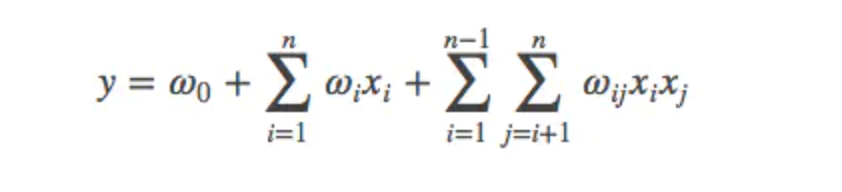
Q2:FM参数求解?
1、公式中,组合部分的特征相关参数共有n(n−1)/2个。在数据很稀疏的情况下xi,xj都不为0的情况非常少,这样将导致ωij无法通过训练得出。
为了求出ωij,我们对每一个特征分量xi引入辅助向量Vi=(vi1,vi2,⋯,vik)。然后,利用vivj^T对ωij进行求解。
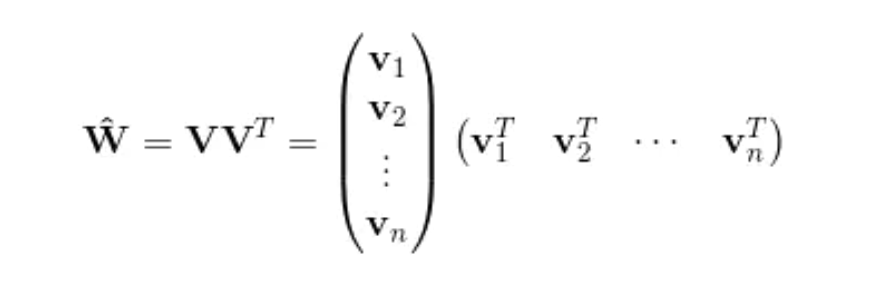
2、如何求解V?
推导公式网上到处都有。
3、得到公式推导结果后,对w求导,梯度下降进行训练。
Q3:FFM?
公式:
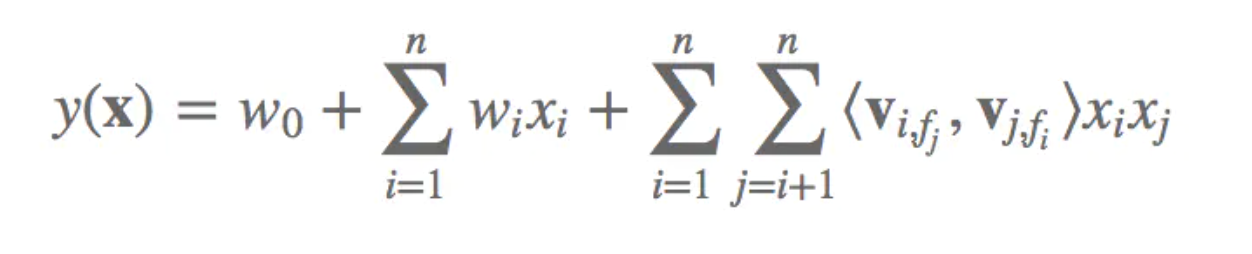
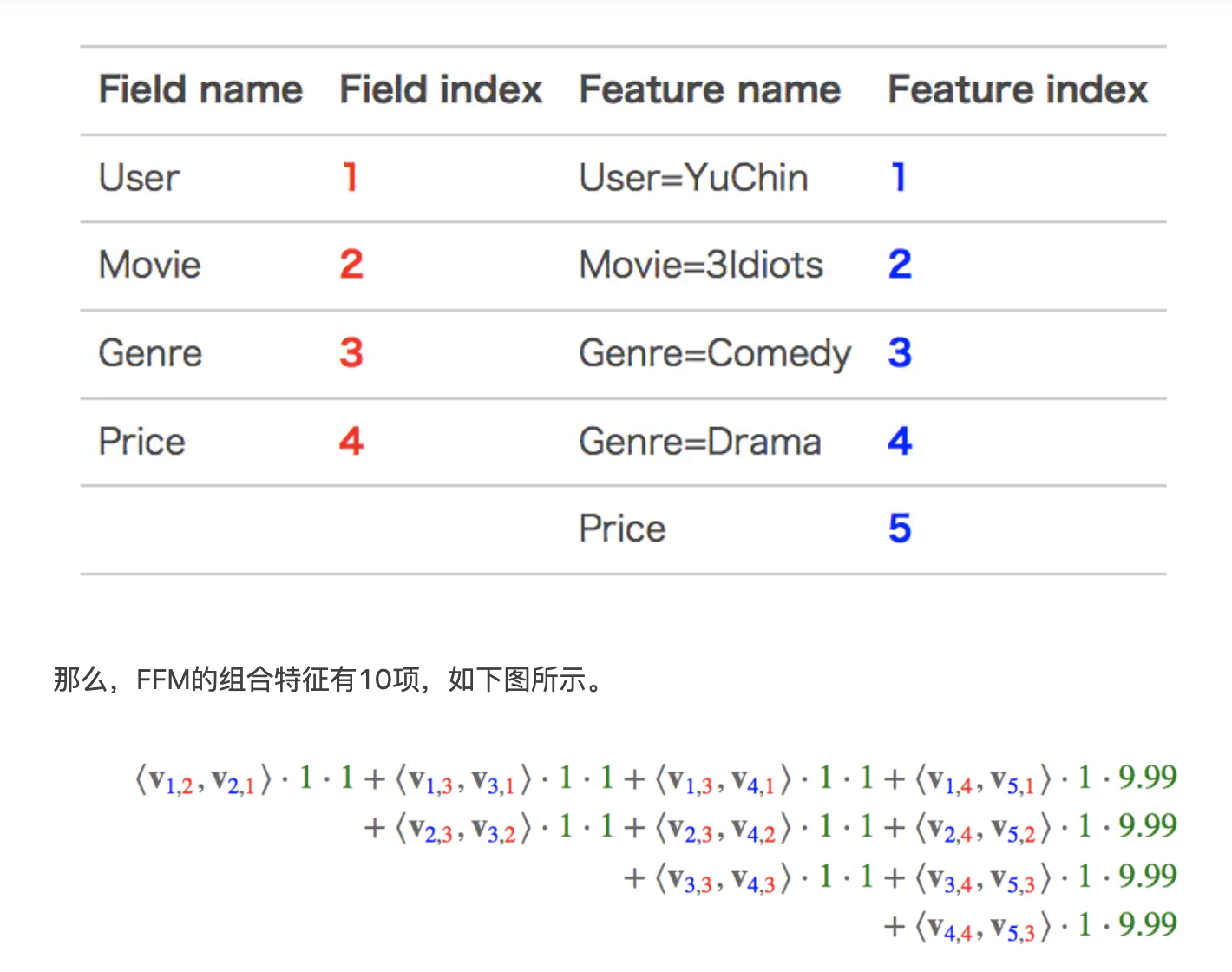
举例:
Q4:why DeepFm?
1、因子分解机(Factorization Machines, FM)通过对于每一维特征的隐变量内积来提取特征组合。最终的结果也非常好。
但是,虽然理论上来讲FM可以对高阶特征组合进行建模,但实际上因为计算复杂度的原因一般都只用到了二阶特征组合。
那么对于高阶的特征组合来说,通过多层的神经网络即DNN去解决。
2、One-hot类型的特征输入到DNN中,会导致网络参数太多。
如何解决这个问题呢,类似于FFM中的思想,将特征分为不同的field:让Dense Vector进行组合,来表示高阶特征。
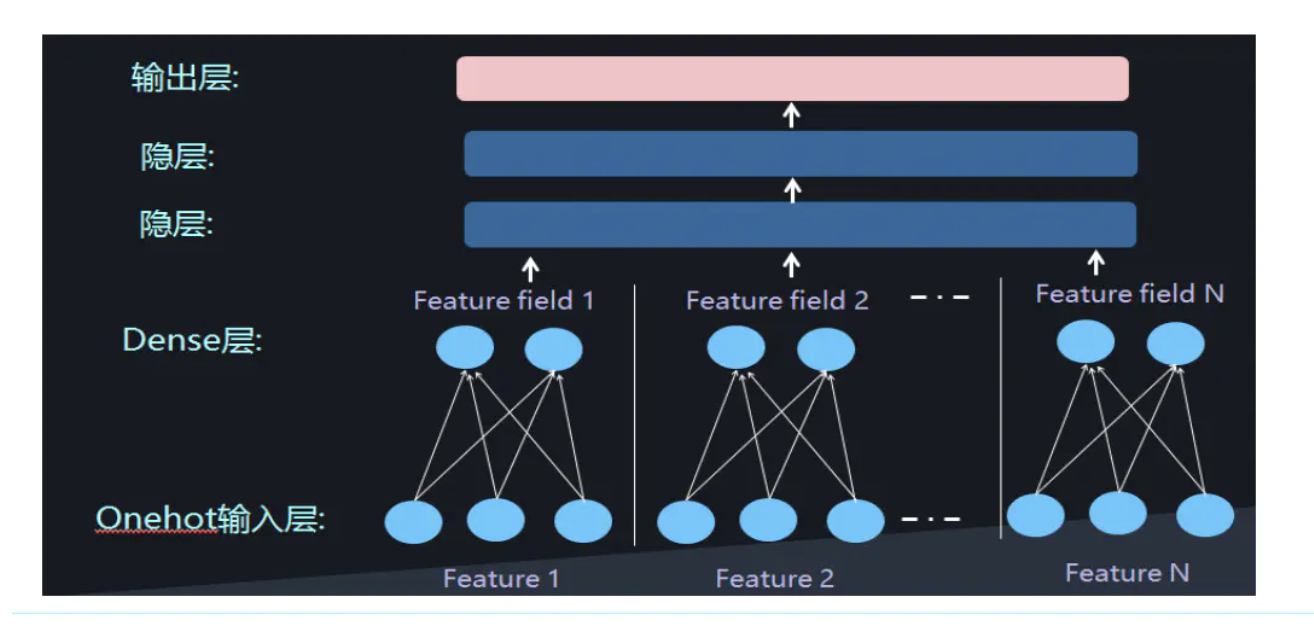
3、但是低阶和高阶特征组合隐含地体现在隐藏层中,如果我们希望把低阶特征组合单独建模,然后融合高阶特征组合。
=>就得到了DeepFm。
Q5:what DeepFm?
1、有两种融合方式,分别为串行和并行的结构。
这里介绍并行结构。
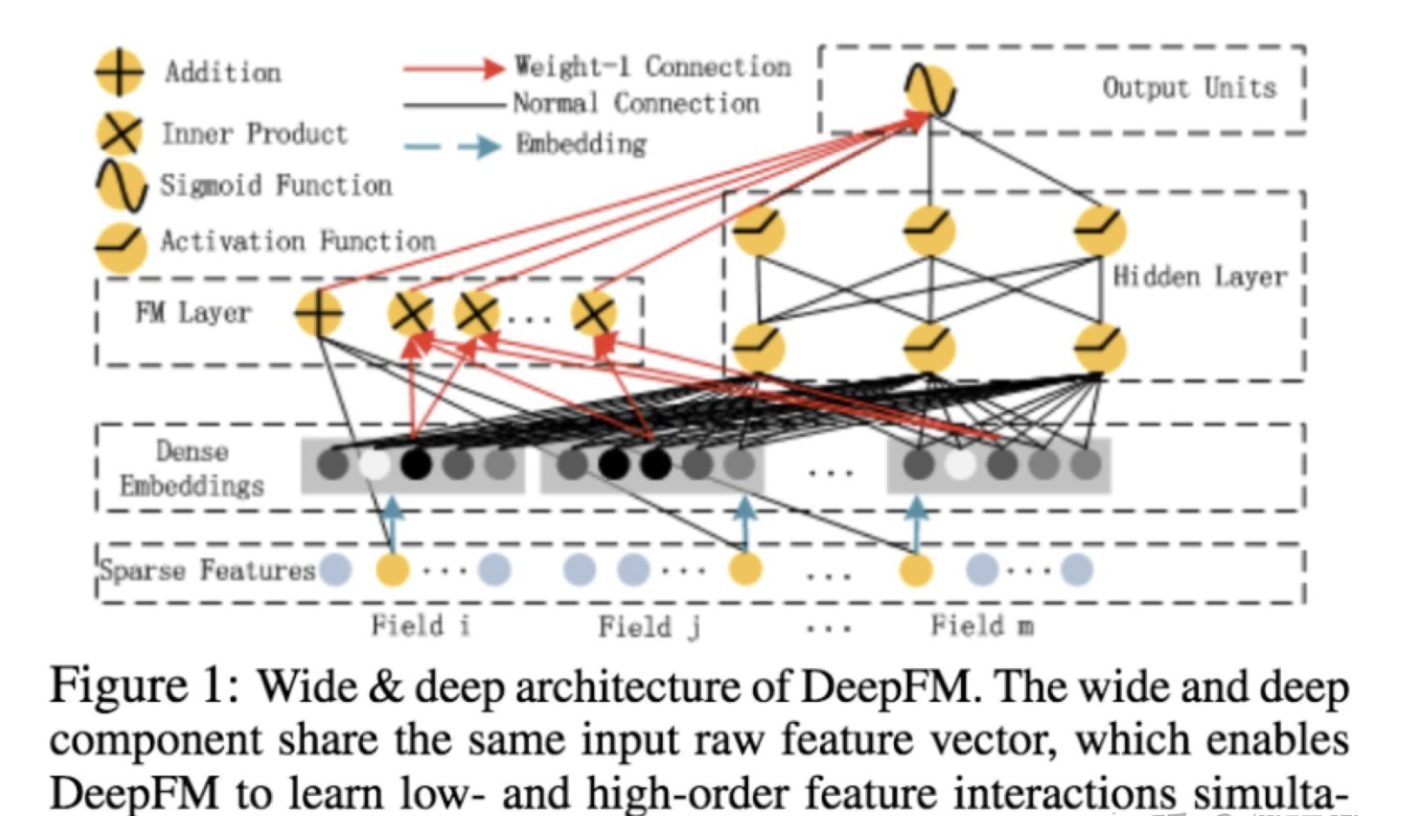
2、emb部分
1 |
|
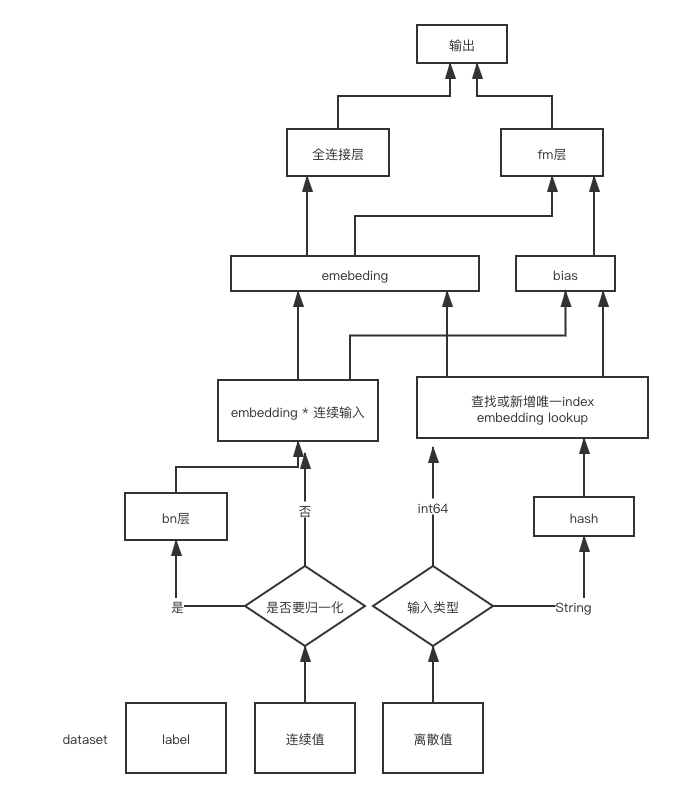
如果是离散值,则embedding lookup之后,每个维度✖️1,连续值则✖️连续值。
✖️后的结果就是公式里的 Vi,f · Xi
3、dnn部分
为了更好的发挥DNN模型学习high-order特征的能力,文中设计了一套子网络结构,将原始的稀疏表示特征映射为稠密的特征向量。
子网络设计时的两个要点:
不同field特征长度不同,但是子网络输出的向量需具有相同维度;
利用FM模型的隐特征向量V作为网络权重初始化来获得子网络输出向量。文中将FM的预训练V向量作为网络权重初始化替换为直接将FM和DNN进行整体联合训练,从而实现了一个端到端的模型。 (即lookup)
4、fm
1 | # second order term |
Q6:扩展,自定义算子?
比如我们输入是每个item的idor一些离散特征时候。需要对离散特征的各个值–>index构建一个table。然后每次输入转换成对应的index,再根据index去tf.nn.embedding_lookup。离散特征对应的weight dict大小,需要给个预估值,大一些,囊括各种离散、连续的取值总数。
这里就可以对tensorflow里的hashtable算子进行扩展。构建一个table,动态增长index,来了一个新的取值,就对应index++。
实现:
1 | Status Find(OpKernelContext* ctx, const Tensor& key, Tensor* value, |
测试:
1 | import tensorflow as tf |
相关命令
1 | 本地: |
本文链接: https://satyrswang.github.io/2021/03/08/DeepFm/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!

