
DSSM
任务
用来预测两个句子的语义相似度,又可以获得某句子的低维语义Embedding向量。场景
DSSM 模型的最大特点就是 Query 和 Document 是两个独立的子网络,后来这一特色被移植到推荐算法的召回环节,即对用户端(User)和物品端(Item)分别构建独立的子网络塔式结构。
两个子网络产生的 Embedding 向量可以独自获取及缓存。
当模型训练完成时,物品的 Embedding 是可以保存成词表的,线上应用的时候只需要查找对应的 Embedding 即可。因此线上只需要计算 (用户,上下文) 一侧的 Embedding,基于 Annoy 或 Faiss 技术索引得到用户偏好的候选集。
- word hashing
word hashing方法是用来减少输入向量的维度,该方法基于字母的n-gram。给定一个单词(good),我们首先增加词的开始和结束部分(#good#),然后将该词转换为字母 [公式] -gram的形式(假设为trigrams:#go,goo,ood,od#)。最后该词使用字母 n-gram的向量来表示。
这种方法的问题在于有可能造成冲突,因为两个不同的词可能有相同的n-gram向量来表示。与原始的ont-hot向量表示的词典大小相比,word hashing明显降低了向量表示的维度。
- 优点
1、解决了LSA、LDA、Autoencoder等方法存在的一个最大的问题:字典爆炸(导致计算复杂度非常高),因为在英文单词中,词的数量可能是没有限制的,但是字母n-gram的数量通常是有限的.
2、基于词的特征表示比较难处理新词,字母的 n-gram可以有效表示,鲁棒性较强
3、使用有监督方法,优化语义embedding的映射问题
4、省去了人工的特征工程
- 缺点
1、word hashing可能造成冲突
2、DSSM采用了词袋模型,损失了上下文信息
3、在排序中,搜索引擎的排序由多种因素决定,由于用户点击时doc的排名越靠前,点击的概率就越大,如果仅仅用点击来判断是否为正负样本,噪声比较大,难以收敛
4、对于中文而言,处理方式与英文有很多不一样的地方。中文往往需要进行分词,但是我们可以仿照英文的处理方式,将中文的最小粒度看作是单字(在某些文献里看到过用偏旁部首,笔画,拼音等方法)
扩展
对DSSM的优化出现了很多的变种,有CNN-DSSM,LSTM-DSSM,MV-DSSM等。trick

- 架构
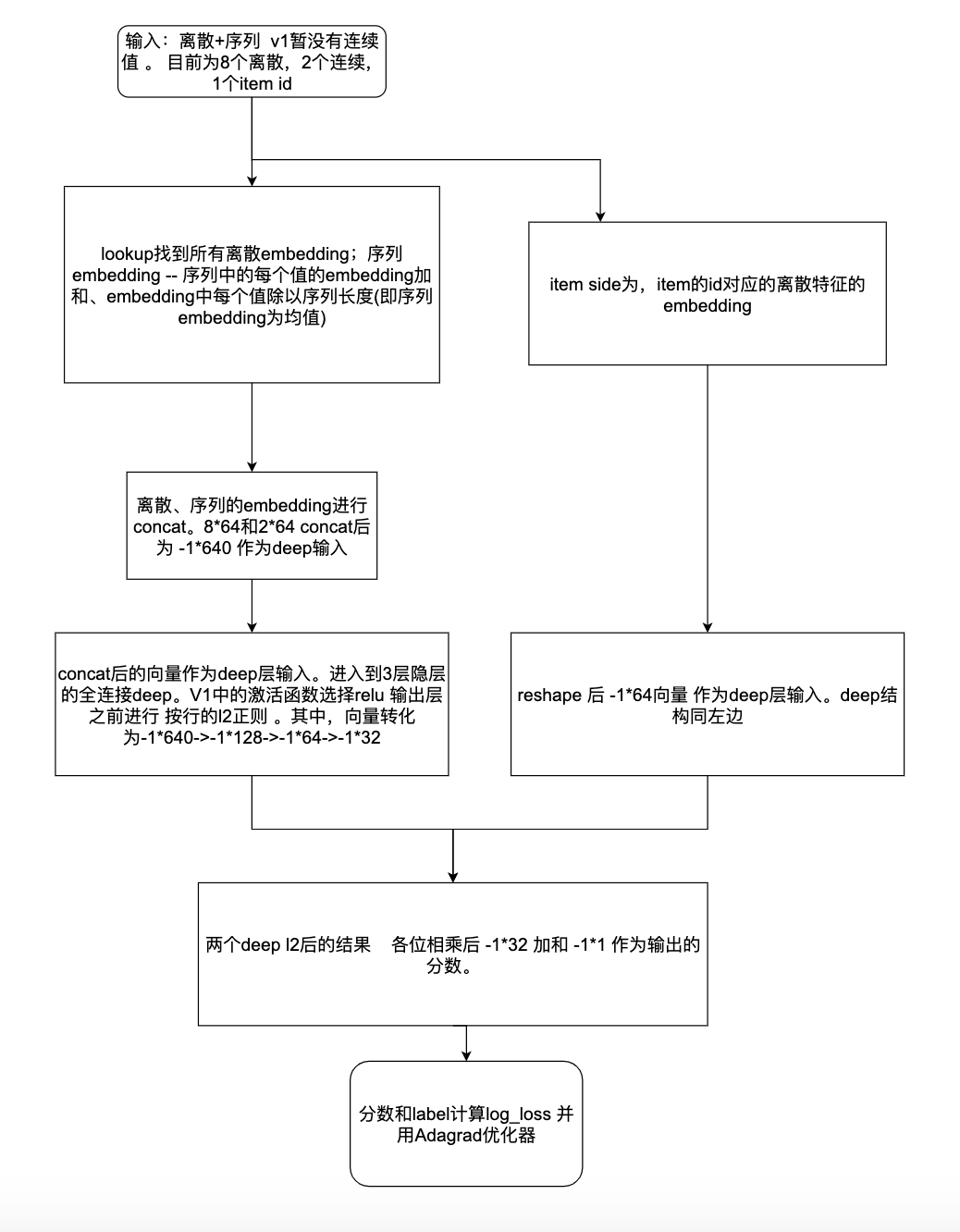
本文链接: https://satyrswang.github.io/2021/03/08/dssm/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!

