
GCN
- 卷积
数学上卷积的两个例子:
一个对象(吃冰淇凌)对一个系统(体重)的作用效果满足线性原理、累加原理。该对象对这个系统连续作用了一段时间后,求该系统的状态。这个时候,一个卷积就可以求出来了!
第二个例子: 
DL中的卷积:
CNN卷积本质是,共享参数的filter过滤器,像素点加权构成feature map 实现特征提取。
a)平滑滤波 b)边缘提取,很容易通过设计特定的“卷积核”,然后将其与像素矩阵的对应元素(不进行旋转)相乘得到。
a)就是将中心像素值与周围临近的像素进行平均,自然就能“削峰填谷”,实现平滑处理
b) 中心像素复制n份,减去周围n个临近的像素值。相近的则减为0,边缘才被留下。
卷积神经网络中“卷积”,是为了提取图像的特征,其实只借鉴了数学卷积中“加权求和”的特点。
为什么需要GCN
CNN LSTM等 对非欧几里得空间数据(eg:社交网络、信息网络等)进行处理上却存在一定的局限性。
用GCN:拓扑图中每个node相邻的个数不同,不能用同样大小的filter进行平移提取feature。任何数据在赋范空间内都可以建立拓扑关联,如谱聚类。GCN是区别于CV NLP的任务的模型。图学习任务
1、图节点分类任务:图中每个节点都有对应的特征,当我们已知一些节点的类别的时候,可以设计分类任务针对未知节点进行分类。我们接下来要介绍的 GCN、GraphSAGE、GAT模型都是对图上的节点分类。
2、图边结构预测任务:图中的节点和节点之间的边关系可能在输入数据中能够采集到,而有些隐藏的边需要我们挖掘出来,这类任务就是对边的预测任务,也就是对节点和节点之间关系的预测。
3、图的分类:对于整个图来说,我们也可以对图分类,图分类又称为图的同构问题,基本思路是将图中节点的特征聚合起来作为图的特征,再进行分类。
如:
1、节点分类—反欺诈:因为图中每个节点都拥有自己的特征信息。通过该特征信息,我们可以构建一个风控系统,如果交易节点所关联的用户 IP 和收货地址与用户注册 IP 和注册地址不匹配,那么系统将有可能认为该用户存在欺诈风险。
2、边结构预测—商品推荐:图中每个节点都具有结构信息。如果用户频繁购买某种类别商品或对某种类别商品评分较高,那么系统就可以认定该用户对该类商品比较感兴趣,所以就可以向该用户推荐更多该类别的商品。
- 拉普拉斯矩阵

GCN主要贡献
这篇文章的主要贡献是为图半监督分类任务设计了一个简单并且效果好的神经网络模型,这个模型由谱图卷积(spectral graph convolution)的一阶近似推导而来,具有理论基础。GCN学习策略
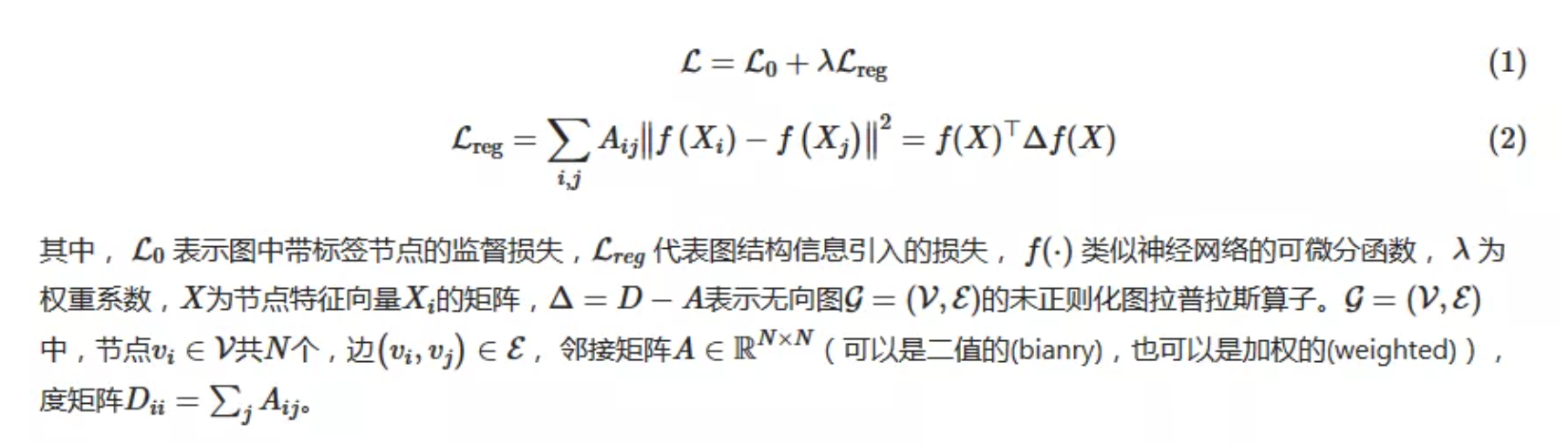
多层图卷积网络(Graph Convolutional Network, GCN)的逐层传播公式

谱图卷积(Spectral Graph Convolutions)
逐层线性模型
半监督学习节点分类
传播公式解释
todo
- gcn聚合时,如果考虑邻居信息和自身信息的占比,用attention呢。但是attention的问题是,fitting训练集,对测试集效果不佳。
graphsage
1、比GCN进步之处
GCN的训练方式需要将邻接矩阵和特征矩阵一起放到内存或者显存里,在大规模图数据上是不可取的。其次,GCN在训练时需要知道整个图的结构信息(包括待预测的节点), 这在现实某些任务中也不能实现(比如用今天训练的图模型预测明天的数据,那么明天的节点是拿不到的)。GraphSAGE的出现就是为了解决这样的问题。
GraphSAGE采用了采样的机制,使得图模型可以应用到大规模的图结构数据中,是目前几乎所有工业上图模型的雏形。
进一步:每个节点这么多邻居,采样能否考虑到邻居的相对重要性呢,或者我们在聚合计算中能否考虑到邻居的相对重要性?
2、inductive 还是 transductive
如果训练时用到了测试集或验证集样本的信息(或者说,测试集和验证集在训练的时候是可见的), 我们把这种学习方式叫做transductive learning, 反之,称为inductive learning. 显然,我们所处理的大多数机器学习问题都是inductive learning, 因为我们刻意的将样本集分为训练/验证/测试,并且训练的时候只用训练样本。然而,在GCN中,训练节点收集邻居信息的时候,用到了测试或者验证样本,所以它是transductive的。
3、简单过程
思路一个网络里,我们知道部分点的分类,我们希望通过各种方法,知道其他未知点的属性。解决对未知节点的泛化问题。
GraphSAGE是一个inductive框架,在具体实现中,训练时它仅仅保留训练样本到训练样本的边。inductive learning 的优点是可以利用已知节点的信息为未知节点生成Embedding. GraphSAGE 取自 Graph SAmple and aggreGatE, SAmple指如何对邻居个数进行采样。aggreGatE指拿到邻居的embedding之后如何汇聚这些embedding以更新自己的embedding信息。
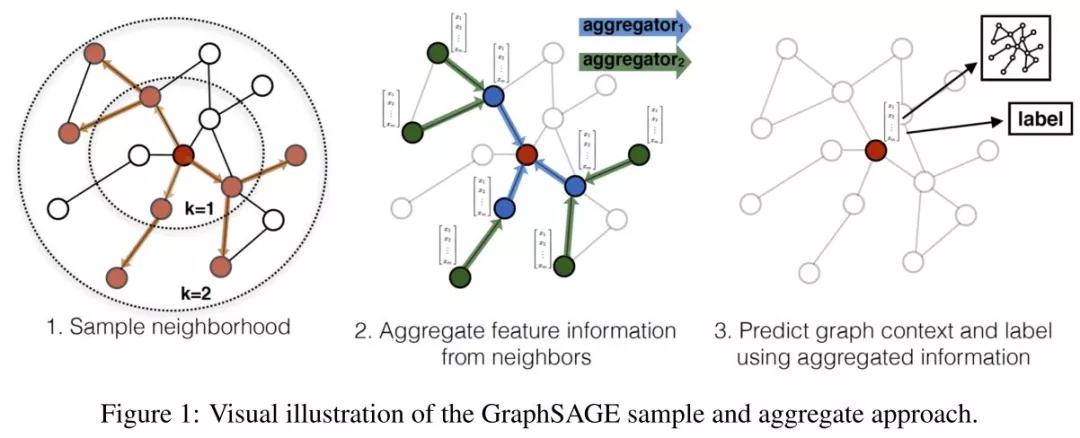
4、具体步骤及伪代码
步骤:
1.对邻居采样
2.采样后的邻居embedding传到节点上来,并使用一个聚合函数聚合这些邻居信息以更新节点的embedding
3.根据更新后的embedding预测节点的标签

描述:初始化各个节点emb,对每个节点emb采样邻居的emb,对邻居进行聚合,将自己的emb和聚合后的emb做一个非线性变换,更新为自己的emb。
5、K的解释
K:聚合器数量,权重矩阵数量,层数。

6、采样
定长抽样。定义邻居个数,进行有放回的重采样/负采样达到个数。每个node采样个数一致,为了把多个邻居拼成tensor放入gpu批量训练。
7、聚合器
平均效果最好。
也有用lstm聚合器和pooling聚合器,
8、学习过程
有监督:交叉熵
无监督:学习出来的相邻node的emb应该尽可能接近。此时的loss如下。

本文链接: https://satyrswang.github.io/2021/03/08/graphsage/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!

