
BERT & Transformer
1 为什么要“微”调[就是transfer learning的一种算法],固定一些底层[for loop],限制搜索空间[本质是正则化],每段层的lr不同,差异大则多训练一些层,减少预训练的权重或者加head来学你的task
2 统计的问题以及为什么要模型。统计无法解决统计自身样本少时候带来的bias & 冷启动
3 TODO :TIMM tfhub - 拿别人的模型用到的库
4 微调加速了收敛 - 靠近中心,损失较为平滑,并且精度变高[最坏精度不变]
5 BERT-encoder GPT-decoder[单向] T5-encoder&decoder all based on transformer。根据你的任务不同选择不同的预训练。比如qa|summarize等一般T5,生成用GPT,情感分类|预测|是否语义等同等用bert
6 TODO:BERT 变种 ALBERT ELECTRA RoBERTa
7 BERT 结构图
8 TODO:BERT应用 - case代码 [命名实体识别、问题答案]
9 bert也体现了模型越大效果越好。GPT3千亿。bert作为特征输入,效果没有在上面finetune更好。合适的prompt对于模型的效果至关重要。
10 TODO:auto-gluon会自动加入微调?
11 resnet是比较常用的cv预训练
12 抖 - 数值稳定性问题
13 TODO:位置编码。偶数计算sin,奇数计算cos。为什么transformer是上面这样固定算的,而bert自己去学习?
14 TODO:ELMO 双向
15 TODO:bpe
16 TODO:rnn显示地学到序列信息,为什么attention比rnn在序列上更好?- 归纳偏置
17 自注意力,没有可学习参数,但是[Transformer多头用]liner后有了
头64 = 512,则8个头。H=512。字典表是30kH。则多头里的参数有HH3+HH。前面是KQV的映射,后面是output的映射。然后是MLP:两层fc,一层的input是H,输出是4H,也是第二层的输入,输入是H。用到的参数是4HH2=HH8。所以一共参数是30kH+51251212block数。当H=786 L=12是110M,1.1亿。
18 mask:pretrain有mask而finetune无,怎么弥合gap => bert是80%mask,10%random,10%不变。
19 bert和transformer的区别 :编解码架构里,编码器看不到解码器的信息。而bert是句子pair进去,两个句子都能看到对方。transfomer输入输出的长度是不变的
20 TODO:bert微调结果不稳定问题:1epoch大些 2微调用完整版的Adam
21 TODO:prompt
对比学习
对比学习有的paper中称之为自监督学习,有的paper称之为无监督学习,自监督学习是无监督学习的一种形式
22 instance discriminate - 个体判别 & memory bank-存储负样本 一个大而一致的字典进行外部学习。将每个输入图片当成一个类,找到一个特征,能在这个空间里将每个类尽量分开。
23 pair-wise loss 、 nce loss\ infoNCE及变体
24 TODO:proximal 正则 让memorybank的数据 - 动量式更新
25 simCLR前身 之 invariant spreading [一个编码器进行端到端的学习 & batchsize太小导致效果不行] :相似的特征和物体保持不变性;正负样本都来自一个minibatch - 效果不很好:因为负样本不够
26 simCLR:强大数据增广&mlp-project
27 cpc:contrastive predictive coding [预测的代理任务来做对比学习] - 多模态对比学习铺垫 & infoNCE loss :每一步最后输出context representation[如果足够好应该可以来预测] -> 用这个预测未来时刻的特征输出。对比学习体现在:正样本是未来输入,得到了未来输出[这些相对于预测出来的输出为正样本]。负样本是任意输入得到的输出[为你预测出来的输出的负样本] [自回归]
28 cmc:contrastive multiview coding 一个物体的 多个视角 都可以作为正样本。每个视角都是有噪声且不完整的。但是最重要的信息[互信息]是在所有视角里共享的。=>如何抓住所有视角的关键特征。
29 cmc的对比学习[多视角的对比学习-多模态的可行性]:4个view - 原始图像、物体分割、离观察者距离、surface normal?。这四个互为正样本 =>演化到 对应图片的文本描述进行多模态学习 =>蒸馏 让teacher和studnt模型输出尽可能相似,并做成正样本对
30 clicp:vit处理图片 & bert处理文本 => ma clip:一个transformer处理多模态数据
31 TODO:teacher和student模型
32 19-20:MoCo Momentum Contrast :类似于instance discriminate。对于memory bank和loss约束做了优化改进。但是改的动量编码器在后面不断被复用,证明了无监督学习可以比有监督更好。
33 TODO:残差网络
34 TODO: MoCov1 - 队列 & 动量编码器 =>第一个下游任务上无监督效果好于有监督 看下吧 https://github.com/mli/paper-reading/
35 simCLR 只是在 var spread上加了数据增强和mlp层,用了更大的batchsize和更多的epoch。提升了10个点 - 无理论解释。 => MoCov2
36 TODO:数据增强- cutout / gaussian noise / gaussion blur / sobel filter / color / crop / rotate /avg
37 simCLRV2 : 无监督学习应用于半监督 - 少部分标签finetune后在无标签数据上自学习/蒸馏。改变3个点:模型更大/fc
层更多-2层[projection head]/增加了MoCo的动量编码器
38 TODO:noisy student
39 TODO:动量编码器 。为什么minibatch很大[4096],负样本足够多,那动量编码器加入到simCLR提升就不那么大了
40 SaAV swapped prediction :对比学习+聚类,一个view得到的特征来预测另一个view的特征。主要是通过聚类,将输出特征和聚类中心,生成q1 q2 ,而q1 q2是输出特征&聚类中心的点乘结果,应该可以互相预测的。聚类中心是有语义的,比随机采样作为负样本要好。
41 TODO: deep cluster 、 deep cluster2 => SwAV
42 SwAV multi crop 降低数据计算。取更小的crop但是增加正样本数量
43 TODO: cpc后的cpcv2 , cmc后的infoMin infoMin【互信息不要最大化而是不多不少,否则泛化不好并且浪费,按照这个思路去优化了数据增强】
44 BYOL :完全不用任何负样本。匹配的问题换成预测的问题,希望query mlp的输出和key的编码器输出尽可能一致。直接是两个向量的mseloss ==>projection &prediction里的 batchnorm遗漏了导致坍塌 ==>因为batchnorm相当于和batch的平均进行隐式地对比学习 => BYOLV2 但是后面的paper进一步反证了并不是进行隐式对比学习。当simCLR没有batchnorm时即使有负样本也不行 == > batchnorm其实是更好地稳定学习,如果初始化会很好即使没有batchnorm也不会坍塌
45 负样本是为了避免学习坍塌 =>只有正样本,很容易造成模型学到一个特征,然后任何输入都用同一个特征,并且输出1,这样loss=0,并且遇到负样本loss会是无穷大,导致坍塌。
46 simSiam :stop gradient导致没有坍塌 => EM算法 为什么等同于EM,还可以理解为一个kmeans? TODO:可以看下。Siamese 孪生网络,因为有两个编码器,结构一样并共享参数。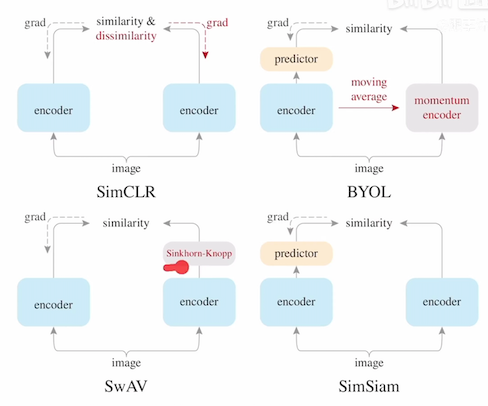
47 MoCo
https://github.com/facebookresearch/moco
伪代码,https://www.bilibili.com/read/cv14620702/
https://blog.csdn.net/qq_42014059/article/details/123988211
a. 意义,填补了 CV 领域的无监督学习和有监督学习的 gap。为什么能,因为CV 原始信号是连续的、高维的,不像单词具有浓缩好的、简洁的语义信息,不适合构建一个字典。如果没有字典,无监督学习很难建模。
b. 代理任务:每个图都是一个类
c. 动量:加权移动平均,当前时刻部分依赖于前一时刻
d. 对比学习 看成 字典查询,动态字典 - 包含队列[里面的样本无需梯度回传 放了很多负样本]和动量编码器[让字典的特征尽量一致]。对比学习和最近的发展,都可以看成是一个训练一个 encoder 来做 字典查询 的任务
e. linear protocol - 预训练特征到新的任务上加最后一层,把 backbone 当成特征提取器
f. 原始的图片经过编码器A,生成的向量为q,而转换的正样本以及其他图片负样本,经过编码器B,生成向量都为k,形成一个字典矩阵K。需要的是K足够大,以及内部特征一致。
g. 最主要是,避免模型进行shortcut学习。如何避免,一个就是动态字典很大 - 大的好处是能够在图片的连续值空间切出来更多的的token特征;一个就是一致,一致的含义是,避免模型qk得到的相似是因为编码器的相似而不是因为特征距离近。两者都是为了避免shortcut问题。
h. 字典大,带来了显卡内存不足的问题,所以选择用队列[current mini-batch enqueued and the oldest mini-batch dequeued ]。一致的问题,因为batch,所以每次出来的k都是不同时刻的编码器输出的结果,那么 - 通过动量编码器,让每次编码器的迭代变慢。
i. 代理任务 和 目标函数的配对学习。MoCo 论文里 instance discrimination 个体判别方法 & examplar based 代理任务很相关;CPC contrastive predictive coding 用上下文信息预测未来 & context auto-encoding 上下文自编码;CMC contrastive multiview coding 利用一个物体的不同视角做对比 & colorization 图片上色(同一个图片的 2 个视角:黑白 和 彩色)
j.代理任务生成自监督的信号,充当 ground truth 的标签信息
k.infoNCE,NCE将类别简化为两类。一个是data sample,一个是noise sample。所有负样本中选择部分算loss。info是多分类。loss里加上了温度超参数,温度小,则logits的分布更为peak,越大则对比损失对所有负样本一视同仁,越小则越加关注于一些特别困难的负样本 - 这样就不好泛化,甚至难收敛。
l.大的batchsize很难收敛,之前的端到端用resnet50作为encoder,但是字典大小就是minibatch大小。然后过渡到memory bank,这里query是每次梯度回传的,而通过把所有数据放到memory bank,离线多次从这个bank里sampling出负样本[idx],存起来,作为训练的正负样本。训练的时候,当前的batch回传则更新bank中idx相应位置的特征,特征是不同时刻得到并更新的,缺乏一致性。并且只有当一个epoch训练完,才能将memory bank 完整更新一次。下一个epoch 不知是上一个epoch哪个时间点更新的。
m.proximal optimization ,让训练更平滑
n.噪声对比估计 -> nce[二分类]。转成多分类则infoNCE。即将softmax 转化为二分类问题与转化为多分类问题,本质是 求原始分布转化为求分类问题。
https://blog.csdn.net/weixin_45104951/article/details/123551076
https://www.aisoutu.com/a/1792120
o.shuffle bn - 数据泄露,走了shortcut
p.为什么label是全0?第一个最大,后面越小越好。
q.去掉hard neg反而更好。 https://github.com/facebookresearch/moco/issues/24
r.nas搜索到lr大于1很夸张的,MOCO里gs是30最好。OMG
s.是不是dense学习不好。=> dense contrast / pixel contrast
48 开始进入Transformer时代。 MoCov3 [相当于V2和simSiam合体] 自监督ViT不稳定,改进:**,然后稳定了。骨干网络从残差变为ViT
观察了训练时,每次回传的梯度情况,发现loss大幅震动时,梯度也会有波峰,在patch projection时候。属于ViT第一层。解决方式就是将这一层随机初始化后直接冻住。
49 DINO centering? 提出了teacher & student
50 CLIP
=>
第一阶段:百花齐放 InstDisc InvaSpread CPC CMC deepcluster
第二阶段:CV双雄 MoCov1 SimCLRv1 MoCov2 SimCLRv2 SWaV
第三阶段:不用负样本 BYOL 针对BYOL的博客和他们的回应 SimSiam
第四阶段:基于Transformer MoCov3 DINO
对抗学习
51 GAN:判别器用leakyrelu ; D G的公式理解 ; MINST的GAN代码demo ;为什么先更新D再更新G ; D为什么不能直接更新到很完美 ; 早期的时候很容易导致log内的值直接为0(整体log的max),怎么做一些数值上的优化改进 ; 证明公式推导
52 DCGan ;conditionalGan ; infoGan ; SSGan ; pix2pix Gan ; cycle Gan ; star Gan
53 swim transformer
a.希望让vision transformer也分成block,像cnn一样进行特征提取。
b.自注意力为了降低序列长度,用patch降低resolution、特征图、小窗口等。这里用了滑动窗口。
c.多尺寸特征,FPN,每层的cnn的感受野是不一样的,可以捕捉到不同尺寸的特征,而VIT只用小窗口只能提取到固定尺寸的特征。
d.TODO:分割,pspnet deeplab Unet提出了skip connection方法解决分割任务的尺寸问题。空洞卷积 psp 等
e.自注意力的复杂度 - 整图上的自注意力 & shift窗口内的自注意力,前者是x平方,后者线性。没有必要全局,因为图片具有连续性。
f.patch merging 、 pixel shuffle
g.复杂度![]()
h.每次是窗口的多头自注意力,然后是移动窗口的多头自注意力。达到窗口间通信。但是移动窗口之后的patch数量和原来的不一致,需要再次 循环移位,移位后由于语义信息变化,需要做mask,再去算自注意力,算完后还原原来的位置。掩码模板图
54 MAE 掩码学习 a.掩码占比过少则模型学的东西简单,这里掩码占75%,加速。vit论文,自监督效果不好,而这里效果更好并且迁移任务也学习得更好。之前是在图片加入噪音然后通过去噪来学习 b.ViT 的作者认为还是需要 有标号的模型、用更大的训练集,效果更好。MAE 使用小数据集 ImageNet-1K 100w 图片,self-supervise 效果很好 c.图片和语言的差别:一个词是语义单元,包含较多语义信息,一个 patch 并不含有一个特定的物体,可能是多个物体的一小块 or 一个物体重叠的一块,即使图片和语言的 masked 的单元包含语义信息不同,MAE or Transformer 可以学到一个隐藏的比较好的语义表达。 d.CNN 在一张图片上,使用一个卷积窗口、不断地平滑,来汇聚一些像素上面的信息 + 模式识别。Transformer 的一个 mask 对应的是一个特定的词,会一直保留,和别的词区分开来。卷积不好加入位置编码?Transformer 需要位置编码:attention 机制没有位置信息,卷积自带位置信息,不断平移时,不需要加入位置信息 e.卷积上做掩码?卷积窗口扫过来、扫过去时,无法区分边界,无法保持 mask 的特殊性,无法拎出来 mask;最后从掩码信息很难还原出来。 f.非对称:编码器和解码器看到的东西不一样。这里用的编码器就是一个vit,即每个patch拿出来做一个线性投影,再加上位置信息,做成一个词,如果mask了则不进入。解码器,是看到了没盖住的块的浅表示,也看到了盖住的块,盖住的都表示成同一个向量,这个向量的值通过学习得到。解码器就要加上位置信息,但是要不要对浅表示也加上位置信息? g.和传统的DAE不同,因为基于了transformer架构。相同是因为,mask相当于在里头加了很多的噪音 h.BEIT给了每个patch一个离散标号,相当于bert的位置编码 i.和IGPT BEIT 和对比学习有什么区别? 重构原始像素和dvae学到的标号? j.对mask住的patch计算loss。对预测的块内的像素做进行normalization ,使像素均值为 0 方差为 1。输入和位置进行线性映射,生成的token序列,把序列打乱,选择前面的25%,然后加上位置信息,再unshuffle下。 k.ViT 文章说 ViT 需要很大的数据才行,其实小一点的数据 + 合适的正则化也可以。
55 DeepMind
56 VIT
a.之前一些把图片输入序列降低的方案,都没有在硬件上有加速,无法进行大规模模型训练。
b.归纳偏置,一个是locality,接近位置有相似性。二个是平移等变性 ->先平移再卷积和先卷积再平移,结果是一样的。这些是卷积的先验信息,所以可以少数据训练。transformer没有这些先验信息,而大规模数据的transformer,会比这种卷积要好。
c.减少序列长度,1local neighborhood,小窗口做自注意力。2sparse transformer。3轴注意力,先横轴再纵轴。4注意力用在不同大小block上
d.image GPT - 生成模型,无监督训练,iGPT在分类任务上很差。而MAE效果却很好了[很火,因为第一次生成网络比判别模型效果好,在检测和分割也好,mae是自监督的方式训练vit的生成模型]
e.卷积神经网络是如何随着数据集增大而提高的
f.cnn mlp每一层都是用到归纳偏置的。为什么自注意力没有归纳偏置
g.卷积是data efficient,而transformer全局建模,将两者混合 => patch到vit,而混合,则是图片先经过卷积[resnet50]出来的特征图也是14*14=196,得到新的patch embeding
h.用位置信息了,那么迁移微调,如果任务的输入图片大小变了,为了保持patch embeding不必拿,则需要 对位置emb进行插值,会损失精度。
i.
57 DETR
58 VIT-FRCNN
59 SETR
60 CLIP
61
其他论文
1 AlexNet
a.本质是压缩,把原始信息压缩成一个向量,机器能够进行计算,用于搜索或者其他任务。
b.通道数,本质是学习到的不同模式。过程是,先慢慢压缩224 224空间的维度,而增加通道数即模式识别的数量。最后转为一个向量。
c.如何变大变深,如何避免过拟合【数据增强-随机抠出一张新的图片 & pca & dropout】,如何利用多个gpu进行卷积【切成两块并行,现在多在nlp大规模模型训练里会并行】
d.饱和激活函数和非饱和激活函数,relu & sigmid,当时觉得relu训练得非常快。但是现在看并不,换一个激活函数问题不大。大家现在用relu还是因为简单。TODO:那激活函数到底还有没有区别,除了梯度消失爆炸问题?
f.local response normalization,现在有更好的归一方式。
g.overlapping pooling
h.8层,5层卷积,3层mlp,最后softmax
i.pca:通道上做了变化,使得每次颜色不一样
j.之前cpu时候,数据增强是性能瓶颈。需要搬到gpu or 用很好的c++方式实现。TODO:gpu加速了什么?
k.dropout为什么避免过拟合,相当于每次训练一个新的模型,而这些新模型之间是部分参数共享的。后来发现其实也不是模型融合,而更多是正则项。TODO:等价l2正则。
l.缺陷:使用了过大的mlp,导致过拟合,需要用dropout来避免,但是拉慢了训练速度。现在的cnn都是会尽量避免大的dense。
m.优化算法用了sgd,现在发现sgd的噪音对收敛是有好处的,虽然调参比较麻烦。weight decay而不叫l2之类,因为更指向是在优化算法上进行衰减,而不是模型本身的正则。里面的momentum保证了,当前的梯度,尽量沿着过去的梯度平缓些前进,避免优化表面过于不平滑而掉落到一个坑里。
n.对学习率的优化,如果发现validation loss不往下降了,会自动将lr0.1。有的会每n epoch将lr0.1,或者进行平滑性地降低。
2 ResNet
a.解决了深度CNN模型难训练的问题,2014年的VGG才19层,而15年的ResNet多达152层
b.56层的网络比20层网络在训练数据上的损失还要大。网络退化问题(Degradation problem)。
c.我们希望说,36层是一个identity mapping,所以至少56层不会比20层差。但是sgd收敛不到这个点。如何通过结构改善,让模型学习到 - 残差连接。即浅层输出x,和深层得到的fx,两个加和,fx+x最为最终的输出。不会增加模型复杂度,不会增加太多训练计算。=>其实也没有完全证明出这种残差链接可以解决这个问题。
d.有残差收敛会快,后期会更好。做了很多random crop和融合来让效果更好。
e.更深,引入了bottleneck[加深的同时不增加太多的浮点数计算,通过映射],越深可抓取更多模式,通道数会增加。
f.后来大家觉得resnet训练比较快,是因为梯度保持的比较好。加的层越多,梯度的乘法因子越多,梯度就会容易消失,但是加了resnet,则有了 “+” 的梯度计算,使得梯度有一定的保持。
g.sgd的收敛没有太大意义,因为大概率是训练不动了。做深了会跑不动,因为梯度越来越小。而加了残差链接,让梯度不那么容易进入收敛,可以继续train。sgd和人生一样,如果哪天跑不动了,其实就局限了。反正你有噪音,只要梯度够,一直跑,慢慢的总是会收敛更好。
h.transformer那么大,1千亿参数,为什么不会小数据集上过拟合呢。=>虽然参数多,层数多,深,但是本质由于你模型的结构,导致内部的复杂度其实不高了。残差链接很可能是使得模型复杂度降低了,相当于找到了一个不是非常复杂的模型而能够拟合。[你自己手动原数据加进去,更容易训练出简单模型来拟合数据]
i.gradient boosting是标号上的residual,而残差是feature上。
3 GNN
a.图上做卷积或者是random walk,等价于将邻接矩阵拿出来做矩阵乘法。pagerank就是很大的图上做随机游走。
b.inductive biaes,图神经网络假设的是图的对称性;不同的汇聚操作;加了attention,对邻接的顶点给权重
c.GCN作为子图函数近似,每层往前走一步?
4 AlphaFold 2
a.编码器:按行 带门的 带pair-bias 的 自注意力
b.按行:
1.每次拿出一行作为输入序列,一行的每个元素是长度c的向量
2.对每个元素 [即c的向量]做投影,得到 q k v,qkv的长度和输入长度一样,都是c
3.多头则多次
4.qk点乘后softmax得到注意力权重,再和v乘
5.多头中间需要多个矩阵,行里的每个元素得到h个长度为c的输出
c.带门:
1.行的每个元素都进行投影, 然后经过sigmoid映射到01之间,然后和上面的输出做按元素乘
2.线性投影学习哪些需要输出哪些不输出
d.pair-bias:
1.当做qk的点乘算分数时,可以拿到pair里的qk对应的向量[这个本身表示了pair的信息],然后这个向量线性投影到1维,2.则原来qk的分数加上这个偏移得到最后的分数
3.最后输出再通过liner投到和原始输入同样长度上
e.
f.mlp模块:将每个元素投影到4倍大小,即c->4c,然后relu,然后再投影回c。这里的4是来自transformer。这里的投影用到的mlp都是共享的,对每个c都是一样的 – 行列的多头自注意力加上这里的mlp,完成了编码器里对MSA空间信息的建模
g.MSA的数据怎样融合到氨基酸pair对的表示呢
1.在MSA里,每个氨基酸是一个矩阵,每一行是每一种生物蛋白质,而氨基酸在每个生物蛋白质中的表示是一个c的向量,所以是一个矩阵。
2.pair表示中,i和j氨基酸之间是一个向量表示关系,假设长度c2。因此我们需要将上面的两个矩阵转换为向量,才能和pair中的表示关联起来。即用liner将两个矩阵都投影的c维,然后再outer product外积。即(s,c,1) product (s,1,c) = (s,c,c),然后对s维度取mean得到(c,c),再将这个矩阵liner投影到c2维度和pair中的c2相加。
h.三角形的自注意力
i.氨基酸对的消息传递
j.解码器 - 不动点注意力 IPA
本质是根据编码器的输入,还原每个氨基酸在3D的位置,即3个坐标点。通过显式地对位置信息进行建模,这里更像一个RNN架构。是每个模块串行。
1.【第i个氨基酸的q和第j个氨基酸的k,做内积,加上来自pair对的偏移bias】A,【把第i个氨基酸的变换T作用在q上,减去,第j个氨基酸的变换作用在k上】B,然后计算这个向量B的距离[这里有个推导:因为是距离和减法,所以全局变换在相减后不受偏移影响了,偏移被减去了,而全局的旋转变换是不影响向量的模的,所以这里不用加全局变换] 得C,再A-C。
2.含义:q是当前氨基酸的位置,k是第j个氨基酸的位置,变换是得到i和j个的氨基酸后面一个氨基酸的位置,如果后面的氨基酸位置相隔比较远,则i和j不应爱相似,即A要减去C。
3.位置信息如何加入的:主干变换的预测如何做的? 一个投影层投到6维,前3是形成变换矩阵需要的3个变量,后3个是偏移。
k.回收机制,将解码出的3d信息和编码的输出一起再输入到编码器,进行循环4次。做成更长的网络,但是不进行误差反传,所以不会造成内存和梯度的问题。
l.正确label的训练出来的模型,预测出来的置信label,也加到训练数据中,但是加一定的噪音。不加噪音直接加预测的label,不准确 - 错上加错。大量的数据增强,和不正确的label,让模型能够学到哪些label不正确?【这里不太对,loss是一样计算的,怎么会识别错误label的样本】
m.和bert一样,训练的时候增加一个mask预测的任务
n.很多细节没讲到的? - 可以再看看其他分析
ps
1 key-value
2 带区间的push pull
3 rpc是不等待的,但是cpu计算之间通过依赖来等待网卡拉到数据 - 顺序、延迟上限
4 不同过滤器 - 系统性能&收敛的影响
5 环上插入节点,环上每段维护一段,对下面连着的两段 进行备份 [向量钟] [一致性hash]
- 哈希算法无法随着扩容缩容自动调整,如果还是按照原来的算法去hash,那会造成大量缓存key时效,对应的服务器读不到数据,导致缓存雪崩
- 假设环为2^32,则每个key映射到环上的一个点,并将服务器映射到环上对应一个点,图片顺时针遇到的第一个服务器为最终缓存的机子。这样每次增加一个服务器,只会导致环上部分数据会失效。
- 但是当hash环上服务器倾斜时,也会导致大部分数据失效,因此引入了虚拟节点,使得真实服务器大概率能够均匀映射到环上的点。
6 延迟倒是不重要,因为可以异步。但是带宽会限制。因此sever先对各个worker进行汇聚 压缩[技术性的压缩 & 稀疏性的压缩],汇聚后再去备份
7 worker的容灾,schedule - ping不同,将task发给其他的worker
paper & author & conference
- MSRA 亚洲研究院,圣地,黄埔军校 - resnet/swimTransformer
- google research
- google brain team
- Alex Krizhevesky 多伦多大学
- Ilya 多伦多大学
- Hinton 多伦多大学
- Alex Davies
- Demis Hassabis
- Pushmeet Kohli
- Kaiming He 【MAE】
- Piotr Dollar 【MAE】
- Ross Girshick 【MAE】
- John Jumper 【AlphaFold】
- TIMM
- tfhub
- nature science
本文链接: https://satyrswang.github.io/2022/10/13/dl-论文/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!

